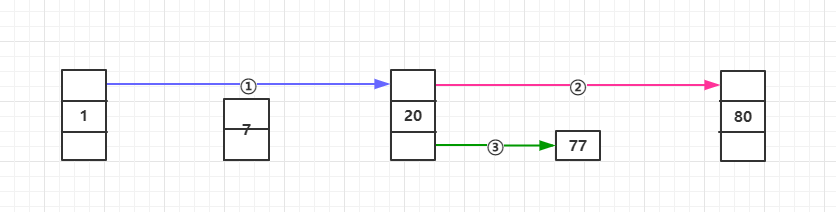
跳跃表(SkipList)既满足了链表增删快的优势,又拥有了列表查询速度快的优势,而它本质上其实就是一个支持二分查找的有序链表,并且在Redis和LeveIDB中都有用到。
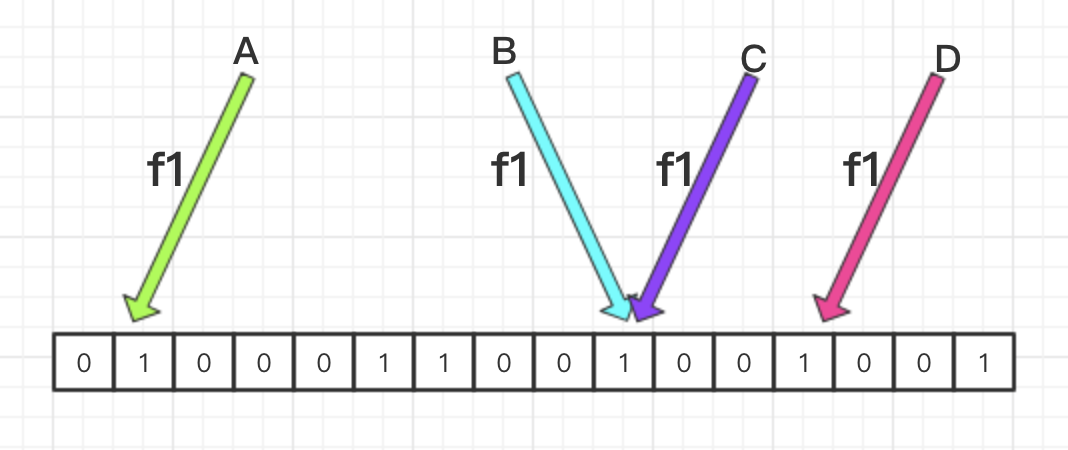
在海量数据处理的场景之下,Bloom Filter 是一种空间效率很高的数据结构,它是一个可以快速判断元素是否存在的概率算法,但是前提是在一定的容错率之下,本文特此进行了一番介绍。
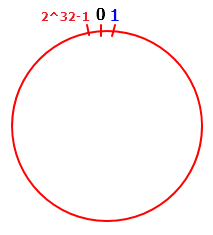
家喻户晓的一致性 Hash 算法是解决数据分散布局或者说分布式环境下系统伸缩性差的优质解,本文旨在使用 Java 语言手动实现一套该算法。
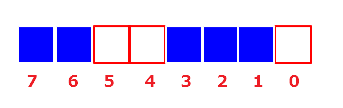
BitMap是一种很常用的数据结构,它的思想的和原理是很多算法的基础,当然,并且在索引,数据压缩,海量数据处理等方面有广泛应用。


本文介绍另一款字符串匹配算法,BM算法,此种算法的优化点在于,pattern 的往后位移量,更大步,而且,原文越大,该算法的优势越明显,因为 BM 算法的瓶颈在于对 pattern 的初始化。

字符串匹配算法有很多种,本文旨在以浅显的语言来说透其中的一款经典算法:KMP

