一、背景
最简单的一个应用场景便是缓存,当单机缓存量过大时需要分库,然后根据相关信息进行 hash 取模运算到指定的机器上去,比如 index = hash(ip) % N。
但是当增加或者减少节点的时候,由于上述公式的 N 值是有变化的,所以绝大部分,甚至说所有的缓存都会失效,对于这种场景最直接的解决办法便是使用一致性 hash 算法。
二、一致性 Hash 算法简介
1、简单的一致性 Hash
关于一致性 Hash 算法,简单的抽象描述就是一个圆环,然后上面均匀布局了 2^32 个节点,比如 [0,1,2,4,8...],然后将我们的机器节点散列在这个圆环上,至于散列的规则,可以使用 hash(ip) 或者 hash(域名)。
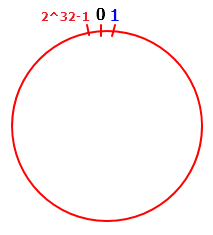
当寻找数据的时候,只需要将目标数据的key散列在这个环上,然后进行顺时针读取最近的一个机器节点上的数据即可。
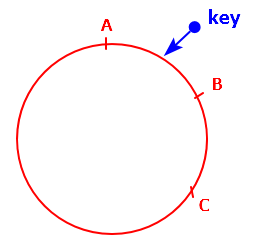
如下图的简单版本,假如总共有3个数据节点(A、B、C),当需要查找的数据的key经计算在A和B之间,则顺时针找,便找到了节点B。
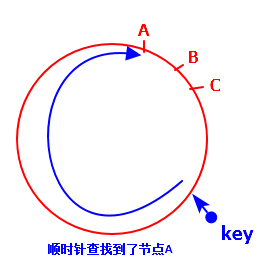
最大的优点是:还是以上面的案例为背景,当节点B宕了之后,顺时针便找到了C,这样,影响的范围仅仅是A和B之间的数据,对于其他的数据是不影响的。
2、虚拟节点
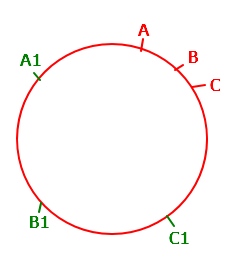
但是在散列数据节点的时候,紧凑性会受 hash 算法的影响,比如A、B、C三个数据服务器,在 hash 计算后散列在 1、2、4三个节点上,这样就会因为太密集而失去平衡性。比如此时我们要查找的数据的key经过 hash 运算之后,大概率是出现在4和1之间的,即在C之后,那样的话顺时针查找便会找到A,那么A服务器便承载了几乎所有的负载,这就失去了该算法的意义。
此时虚拟节点便出现了,比如上述的三台服务器各虚拟分裂出1各虚拟节点(A1、B1、C1),那么这样便可以在一定程度上解决一致性hash的平衡性问题。
三、数组简陋版
1、思路
简单描述下思路:其实就是使用一个数组去存储所有的节点信息,存完之后需要手动排序一下,因为是有序的,所以取的时候就从 index 为0开始挨个对比节点的 hash 值,直到找到一个节点的 hash 值是比我们的目标数据的 hash(key) 大即可,否则返回第一个节点的数据。
2、代码其实很简单,直接撸:
package com.jet.mini.utils;
import java.util.Arrays;
/**
* @ClassName: SortArrayConsistentHash
* @Description: 初代数组实现的一致性哈数算法
* @Author: Jet.Chen
* @Date: 2019/3/19 23:11
* @Version: 1.0
**/
public class SortArrayConsistentHash {
/**
* 最为核心的数据结构
*/
private Node[] buckets;
/**
* 桶的初始大小
*/
private static final int INITIAL_SIZE = 32;
/**
* 当前桶的大小
*/
private int length = INITIAL_SIZE;
/**
* 当前桶的使用量
*/
private int size = 0;
public SortArrayConsistentHash(){
buckets = new Node[INITIAL_SIZE];
}
/**
* 指定数组长度的构造
*/
public SortArrayConsistentHash(int length){
if (length < 32) {
buckets = new Node[INITIAL_SIZE];
} else {
this.length = length;
buckets = new Node[length];
}
}
/**
* @Description: 写入数据
* @Param: [hash, value]
* @return: void
* @Author: Jet.Chen
* @Date: 2019/3/19 23:38
*/
public void add(long hash, String value){
// 大小判断是否需要扩容
if (size == length) reSize();
Node node = new Node(value, hash);
buckets[++size] = node;
}
/**
* @Description: 删除节点
* @Param: [hash]
* @return: boolean
* @Author: Jet.Chen
* @Date: 2019/3/20 0:24
*/
public boolean del(long hash) {
if (size == 0) return false;
Integer index = null;
for (int i = 0; i < length; i++) {
Node node = buckets[i];
if (node == null) continue;
if (node.hash == hash) index = i;
}
if (index != null) {
buckets[index] = null;
return true;
}
return false;
}
/**
* @Description: 排序
* @Param: []
* @return: void
* @Author: Jet.Chen
* @Date: 2019/3/19 23:48
*/
public void sort() {
// 此处的排序不需要关注 eqals 的情况
Arrays.sort(buckets, 0, size, (o1, o2) -> o1.hash > o2.hash ? 1 : -1);
}
/**
* @Description: 扩容
* @Param: []
* @return: void
* @Author: Jet.Chen
* @Date: 2019/3/19 23:42
*/
public void reSize() {
// 扩容1.5倍
int newLength = length >> 1 + length;
buckets = Arrays.copyOf(buckets, newLength);
}
/**
* @Description: 根据一致性hash算法获取node值
* @Param: [hash]
* @return: java.lang.String
* @Author: Jet.Chen
* @Date: 2019/3/20 0:16
*/
public String getNodeValue(long hash) {
if (size == 0) return null;
for (Node bucket : buckets) {
// 防止空节点
if (bucket == null) continue;
if (bucket.hash >= hash) return bucket.value;
}
// 防止循环无法尾部对接首部
// 场景:仅列出node的hash值,[null, 2, 3...],但是寻求的hash值是4,上面的第一遍循环很显然没能找到2这个节点,所有需要再循环一遍
for (Node bucket : buckets) {
if (bucket != null) return bucket.value;
}
return null;
}
/**
* node 记录了hash值和原始的IP地址
*/
private class Node {
public String value;
public long hash;
public Node(String value, long hash) {
this.value = value;
this.hash = hash;
}
@Override
public String toString() {
return "Node{hash="+hash+", value="+value+"}";
}
}
}3、弊端
① 排序算法:上面直接使用 Arrays.sort() ,即 TimSort 排序算法,这个值得改进;
② hash 算法:上文没有提及 hash 算法,需要改进;
③ 数据结构:上文使用的是数组,但是需要手动进行排序,优点是插入速度尚可,但是扩容不便,而且需要手动排序,排序的时机也不定,需要改进;
④ 虚拟节点:没有考虑虚拟节点,需要改进。
四、TreeMap 进阶版
上文的实现既然有弊端,那就操刀改进之:
① 数据结构:我们可以使用 TreeMap 数据结构,优点是该数据结构是有序的,无需再排序,而且该数据结构中有个函数叫 tailMap,作用是获取比指定的 key 大的数据集合;
② hash 算法:此处我们使用 FNV1_32_HASH 算法,该算法证实下来散列分布比较均匀,hash 碰撞尚且 ok;
③ 虚拟节点:我们暂且设置每个节点锁裂变的虚拟节点数量为10。
代码也不难,也是直接撸:
package com.jet.mini.utils;
import java.util.SortedMap;
import java.util.TreeMap;
/**
* @ClassName: TreeMapConsistentHash
* @Description: treeMap 实现的进化版一致性hash
* @Author: Jet.Chen
* @Date: 2019/3/20 20:44
* @Version: 1.0
**/
public class TreeMapConsistentHash {
/**
* 主要数据结构
*/
private TreeMap<Long, String> treeMap = new TreeMap<>();
/**
* 自定义虚拟节点数量
*/
private static final int VIRTUAL_NODE_NUM = 10;
/**
* 普通的增加节点
*/
@Deprecated
public void add (String key, String value) {
long hash = hash(key);
treeMap.put(hash, value);
}
/**
* 存在虚拟节点
*/
public void add4VirtualNode(String key, String value) {
for (int i = 0; i < VIRTUAL_NODE_NUM; i++) {
long hash = hash(key + "&&VIR" + i);
treeMap.put(hash, value);
}
treeMap.put(hash(key), value);
}
/**
* 读取节点值
* @param key
* @return
*/
public String getNode(String key) {
long hash = hash(key);
SortedMap<Long, String> sortedMap = treeMap.tailMap(hash);
String value;
if (!sortedMap.isEmpty()) {
value = sortedMap.get(sortedMap.firstKey());
} else {
value = treeMap.firstEntry().getValue();
}
return value;
}
/**
* 使用的是 FNV1_32_HASH
*/
public long hash(String key) {
final int p = 16777619;
int hash = (int)2166136261L;
for(int i = 0; i < key.length(); i++) {
hash = (hash ^ key.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0) hash = Math.abs(hash);
return hash;
}
}五、其他
1、虚拟节点的数量建议:
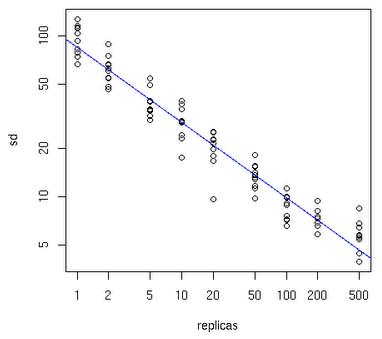
看上图,X 轴是虚拟节点数量,Y 轴是服务器数量,很显然,服务器越多,建议的虚拟节点数量也就越少。



文章评论
直接 ceilingEntry 获取到更大的第一个值不是更好吗。为啥要用 tailMap 呢
写的真好,清晰明了