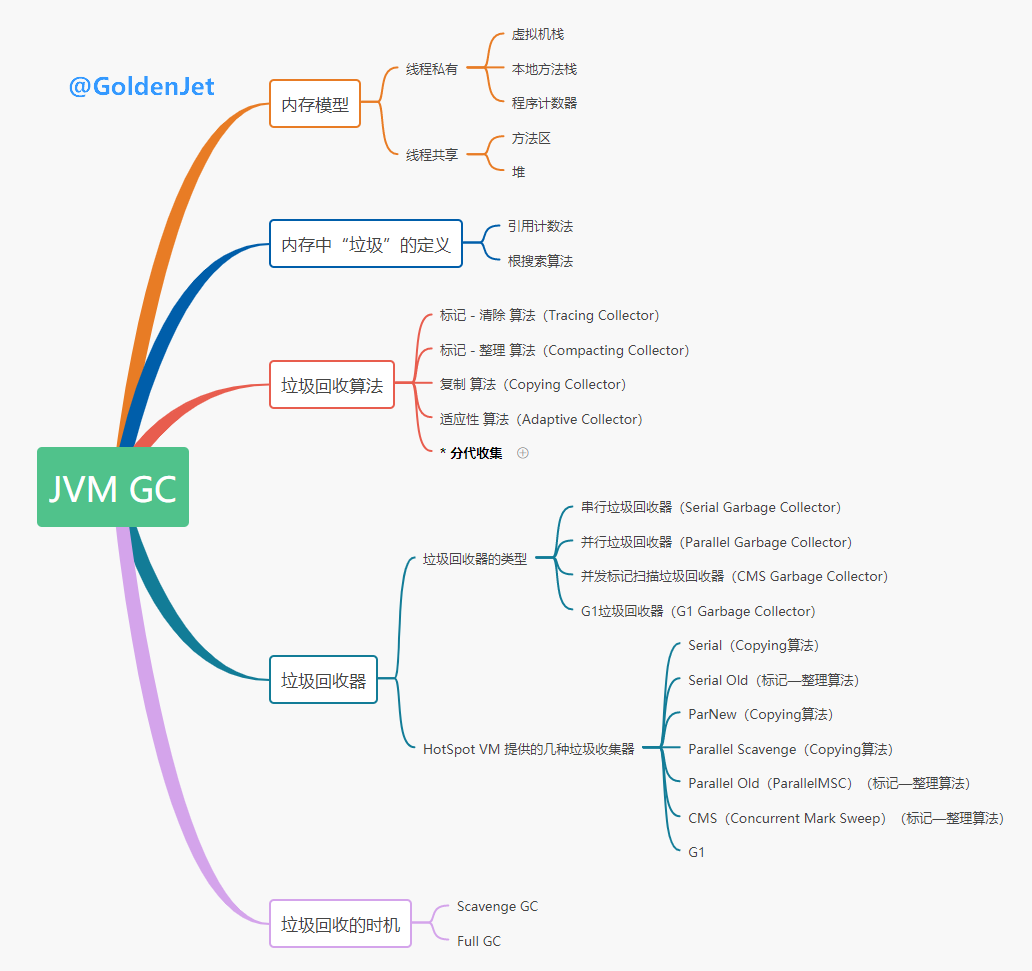
我们知道,程序在运行的时候,为了提高性能,大部分数据都是会加载到内存中进行运算的,有些数据是需要常驻内存中的,但是有些数据,用过之后便不会再需要了,我们称这部分数据为垃圾数据。 为了防止内存被使用完,我们需要将这些垃圾数据进行回收,即需要将这部分内存空间进行释放。不同于 C++ 需要自行释放内存的机制,Java 虚拟机(JVM)提供了一种自动回收内存的机制,这对于我们开发人员来说,再友好不过了。
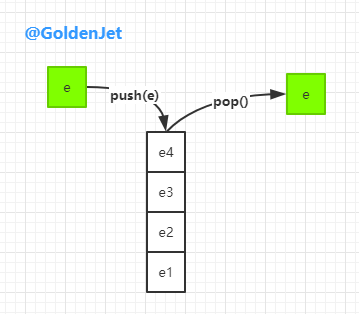
堆栈(Stack)数据结构也是常用的数据结构之一,但是官方建议使用 Deque 这种双边队列才替代之,所以,本文就对 Deque 这种数据结构进行详细地剖析下。
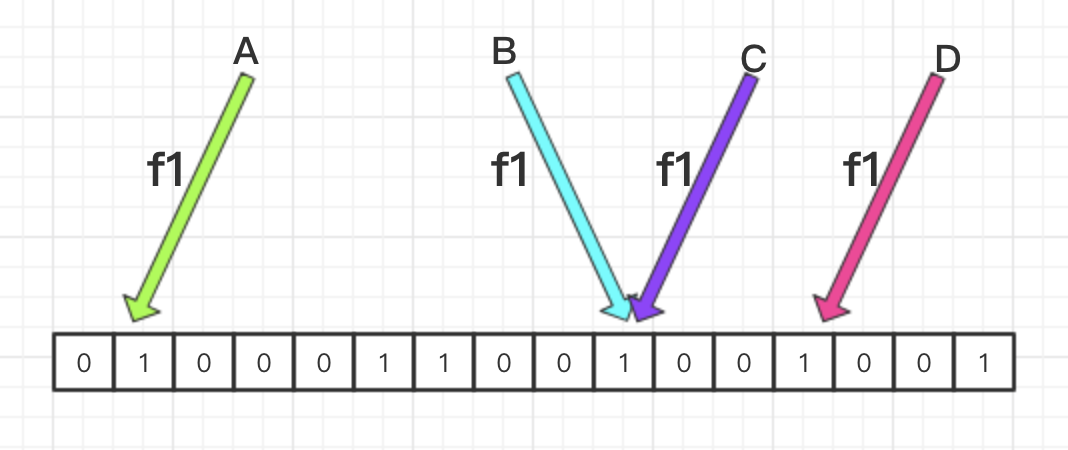
在海量数据处理的场景之下,Bloom Filter 是一种空间效率很高的数据结构,它是一个可以快速判断元素是否存在的概率算法,但是前提是在一定的容错率之下,本文特此进行了一番介绍。
家喻户晓的一致性 Hash 算法是解决数据分散布局或者说分布式环境下系统伸缩性差的优质解,本文旨在使用 Java 语言手动实现一套该算法。
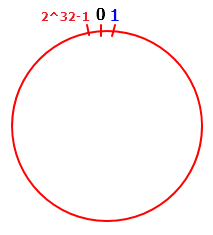
BitMap是一种很常用的数据结构,它的思想的和原理是很多算法的基础,当然,并且在索引,数据压缩,海量数据处理等方面有广泛应用。

此文旨在介绍 double 这种浮点型数值在进行计算的过程中产生的精度问题,并介绍十进制的小数和二进制之间的转换。


本文介绍另一款字符串匹配算法,BM算法,此种算法的优化点在于,pattern 的往后位移量,更大步,而且,原文越大,该算法的优势越明显,因为 BM 算法的瓶颈在于对 pattern 的初始化。

字符串匹配算法有很多种,本文旨在以浅显的语言来说透其中的一款经典算法:KMP
