一、简介
BitMap 是一种很常用的数据结构,它的思想和原理是很多算法的基础,比如Bloom Filter 。
BitMap 的基本原理就是用一个 bit 位来存放某种状态(如果理解不了,看完下文再回头来看即可),适用于拥有大规模数据,但数据状态又不是很多的情况。通常是用来判断某个数据存不存在的。
它最大的一个特点就是对内存的占用极小,所以经常在大数据中被优化使用。
为什么说占用内存小呢?其实从名字就可以看出端倪,直译过来叫位图,但不是图形学里面的位图哦,关键单词是Bit。比如通过某种方法用一个 bit 来表示一个 int,这样的话内存足足压缩至 1/32(1 int = 4 byte = 32 bit,PS:理论计算而已,实操时并不会有 1/32 这么夸张,下文会解释),所以原先需要8G内存的数据,现在只需要256M,岂不乐哉?当然了,其中算法的一些概念在下文会详解。
二、初窥 BitMap
1、概念理解
所谓的 BitMap 就是用一个 Bit 位来标记某个元素对应的 Value, 而 Key 即是该元素。由于采用了 Bit 为单位来存储数据,因此在存储空间方面,可以大大节省。
比如有个 int 数组 [2,6,1,7,3],内含5个元素,存储的空间大小为 5 * 32 = 160 bit,取的时候,使用元素的下标来获取对应位上的元素。
但是如果换种思路,把元素的值作为下标,每个下标位使用 bit 来标记,有值则为1,否则为0,此时我们只需要在内存上开辟一个连续的二进制位空间,长度为8(因为上面数据最大的元素是7,但是需要考虑下标起点为0),则可以表示成:
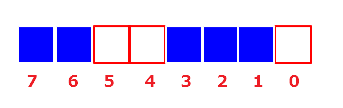
说明:初始化一个长度是8的 BitMap,初始值均为0,然后将[2,6,1,7,3]填入对应的下标处,上图中蓝色域,即将这几个下标处的值设置为1,所以表示为:1 1 0 0 1 1 1 0。此时占用的内存空间为 8 bit,而原来是 160 bit(顺便解释下上文提到的 1/32,因为我们开辟的是连续的内容空间,所以会有冗余)。
2、案例说明
① 案例一:还是上文的数组,需求是查询元素6是否在数组中。
原先我们需要遍历整个数组,时间复杂度为 O(n);
而现在我们只需要查验下标为6的字节是0还是1即可,如果是1,则代表存在,时间复杂度直接降为 O(1)。
所以,最直接的应用场景便是:数据的查重。
② 案例二:有两个数组,判断这两个数组中的重复元素。
原先的最浅显的做法是双层for循环进行判断比较。
而现在,只需要将转换完成的两个BirMap进行与运算即可,如:11001110B & 10100000B = 10000000B,所有得出结果,只有元素 7 重复。
当然,最直接的应用场景是:每个客户都有不同的标签,当需要查找同时符合标签a和标签b的客户的时候,只需要将标签a和标签b的客户查出来进行如上的与运算即可。
3、补充说明
① 实际使用的时候,并不会向上面一样很随意地将长度设置为8,一般会设置为32(int型)或64(long型),理由见下文 BitSet 源码即可。
② 除了上文提到的与运算,当然了,逻辑或和逻辑异或操作都是OK的。
③ 每个Bit位只能是0或1,所以只能代表true or false,当我们要进行少量统计的时候,可以使用2-BitMap,即每个位上可以使用 00、01、10、11来分别表示数量为 0、1、2,此时的 11 一般无意义。
三、BitSet 源码
1、简述
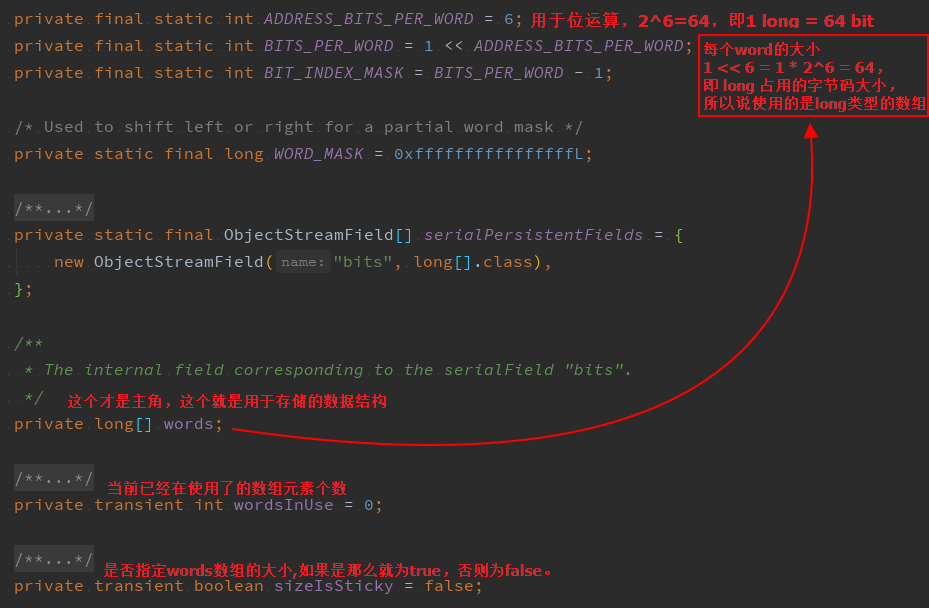
对于 BitMap 这种经典的数据结构,在 Java 语言里面,其实已经有对应实现的数据结构类 java.util.BitSet 了(@since JDK1.0),而 BitSet 的底层原理,其实就是用 long 类型的数组来存储元素,所以回过头来看上文提到的为什么实际使用的时候,长度一般会是有规则的,因为此处使用的是long类型的数组,而 1 long = 64 bit,所以数据大小会是64的整数倍。
/**
* The internal field corresponding to the serialField "bits".
*/
private long[] words;至于 Java 中的 BitSet 为什么使用 long 数组而不使用 int 数组,我觉得应该是出于 Java 语言的性能考虑的,因为在进行逻辑与等一系列位运算的时候,是需要将两个数组中的元素一一进行位运算的,而使用 long 的一个好处是数组的长度减少了,从而遍历的次数也就减少了。
总之就是和场景有关系,抽象概念上就有点类似 Java 中字符串的匹配算法(indexOf)使用的是 BF(暴力检索)算法一样,为什么不用更优解呢?还不是因为更优解在少量数据的情况下反而是拖后腿的那一位。
2、成员变量
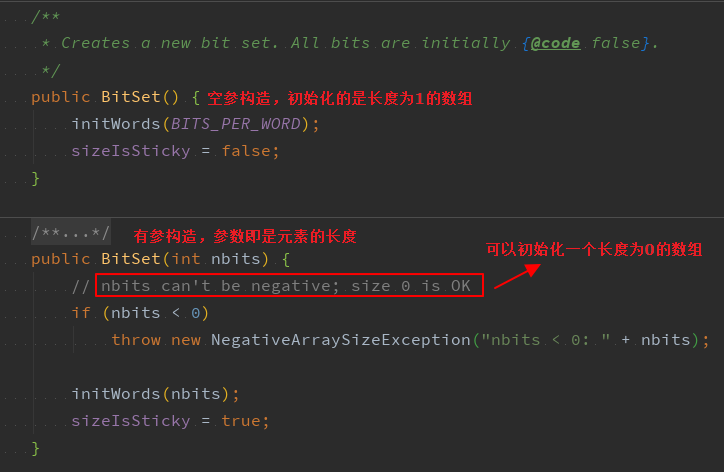
3、构造方法
有参构造的参数代表的是元素的长度,不是数组的大小,比如传参1和64,数组的长度均为1,整个size均为64,但是传参65的时候,数组长度为2,size为128,因为数组是long类型,而一个long可以存储64个bit元素。
4、 initWords 函数
该函数只在两个构造方法中调用,作用是初始化数组,而数组的长度则会通过 workIndex(nbits-1) + 1 来获取。
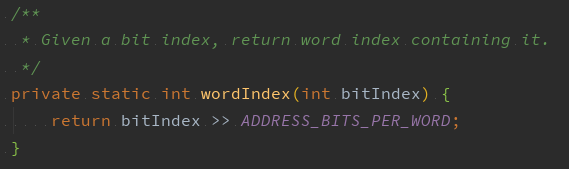
5、 wordIndex 函数
这个方法很重要, 它是用来获取某个数在 words 数组中的索引的,采用的算法是将这个数右移6位,why?因为 bitIndex >> 6 == bitIndex / (2^6) == bitIndex /64,而long就是64个字节。
6、ensureCapacity 函数
又是一个很重要的方法,作用是动态扩容,因为在初始化的时候,我们并不知道将来会需要存储多大的数据。

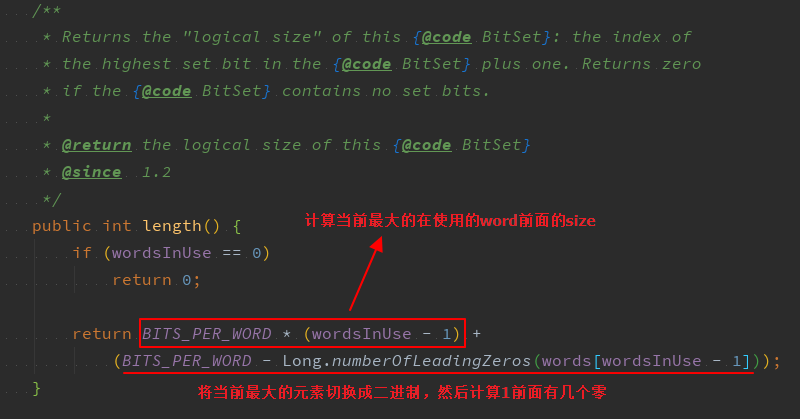
7、size 和 length 函数
size 方法很好理解,返回的其实就是数组的空间大小,即数组长度*64。
而 length 方法,看源码其实有点晦(qu)涩(qiao),简言之,返回的是 BitSet 的“逻辑大小”,即BitSet 中最高设置位的索引加 1 。
举个栗子,一个 BitSet 中存储了两个元素,10和50,那么,此时这个 BitMap 的:size = 64;length = 51。
8、题外话
其余的 set、get等方法暂不赘述,总之一句话,想要深刻理解 BitSet 的源码,对于二进制的计算需要有一定的掌握水准。不得不承认,BitSet 的源码,很多细节的设计太精妙了。
四、拓展
如要论述拓展,要么就是论述场景的高层次应用,要么就是论述此算法的不足之处,此处各提一个点:
① 不足:数据稀疏问题,比如三个元素(1,100,10000000),则需要初始化的长度为 10000000,很不合理,此时可以使用 Roaring BitMap 算法来解决,而 Java 程序可以使用goolge的 EWAHCompressedBitmap 来解决。
② 拓展:数据碰撞问题,比如上文提到的爬虫应用场景是将URL进行哈希运算,然后将hash值存入BitMap之中,但是不得不面临一个尴尬的情况,那就是哈希碰撞,而布隆算法(Bloom Filter)就可以解决这个问题,为什么是拓展呢?因为它是以 BitMap 为基础的排重算法。



文章评论